The Relational Database Access Layer Pattern Language provides a uniform mechanism for efficient database accesses and encapsulation of database system aspects. The pattern applies as a persistence mechanism for data abstraction modules and NOT as a full fledged object/relational access layer, but serves only as the Tuple Layer part of it
You are writing a business information system like the preceding order processing system. The relational calculus is an appropriate representation of the domain logic. The resulting data model is simple and uses inheritance sparingly. The effort of mapping the relational model to an object-oriented representation is high compared to the gains.
How do you access the relational database?
The forces influencing the design of a Relational Database Access Layer have been described above in more detail. They are:
Separation of concerns versus cost of programming.
Ease-of-use versus power of an interface.
Performance of the resulting solution.
Flexibility versus complexity.
Possible integration of legacy systems versus optimal design for non legacy data.
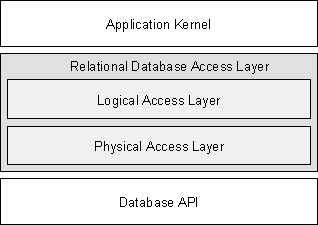
Use a layered architecture consisting of two layers. The Logical Access Layer provides the stable application kernel’s interface, while the Physical Access Layer accesses the database system. The latter may adapt to changing performance needs. Use a Query Broker to decouple both layers.
Figure 4 shows the classes of the Relational Database Access Layer. The Logical Access Layer provides classes for caching and transaction management. The Physical Access Layer represents the interface to the database system. The latter splits into the physical views, representing data access, and the Database class, which encapsulates administrative calls. Hardwired logic or - even better - a Query Broker mediates between the logical and the physical access layer.
offers an interface that allows start(), commit()and rollback() of transactions.
is created at the beginning of every transaction. It is destroyed after a commit() or an abort(). This usage resembles the transaction object defined in [ODMG96, chapter 2.8].
delivers data identified by a key. Therefore it offers createView() and getView() methods to create new Views and activate existing ones. These two methods are the only way for the Client to get a reference to a View.
uses a View Cache to avoid creating Views if they already exist in the context of the current transaction.
allows predicates to identify ConcreteViews. An abstract key class ViewKey provides a standard interface for all keys.
is a Singleton [GOF95].
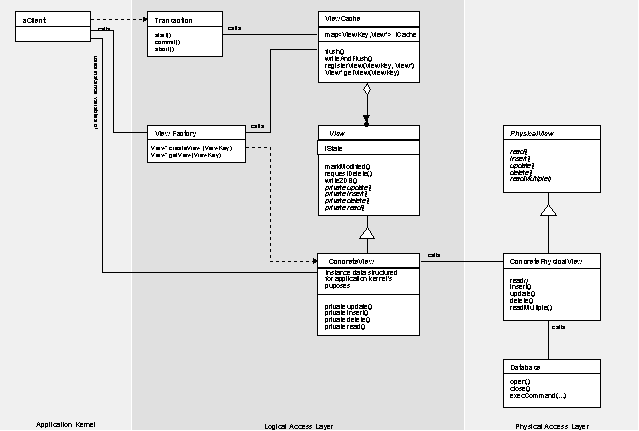
Figure 4 : The structure of the Relational Database Access Layer framework. The Client accesses only classes of the Logical Access Layer, which, in turn, use the Physical Access Layer to connect to the database.
prevents data from being loaded twice. It is a keyed Container of Views forming the access layer’s cache.
offers the writeAndFlush method, which writes all modified Views to the database using their write2DB method. The Transaction object calls writeAndFlush when it commits. Upon abort Transaction calls the flush() method to clear the ViewCache instead.
is a Hierarchical View on the logical data model. There are several ConcreteView classes, each of them tailored for one or more use cases of the application kernel. Members of ConcreteViews are application data types, not raw database types[1].
knows how to write itself to the database using ConcretePhysicalViews. The ConcreteView keeps track of its internal state and calls private update(), insert() or delete() methods if it receives a write2DB() message from the ViewCache. You may use a hard coded calls to suitable ConcretePhysicalViews or a Query Broker.
View
defines the abstract protocol for ConcreteViews. See also the Hierarchical View pattern.
offers a markModified() method to cause a database update when the current transaction commits.
provides the requestDelete() method to generate a database delete at the end of a transaction. Do not confuse this method with a destructor. While the destructor instantly eliminates the objects from memory, requestDelete() sets a delete flag. On end of a transaction the object is later erased from the database (and from memory). To avoid dangling references, the requestDelete() method should be the only way to delete database records.
PhysicalView
defines a uniform protocol for ConcretePhysicalViews.
wraps one physical database table. It may also wrap database views. If the database does not support direct update of views, the ConcretePhysicalView also issues the appropriate write commands.
bundles database access functions, encapsulates database behavior and translates database error codes into application level errors[2].
also wraps database optimization if you use Denormalization, Controlled Redundancy, or Overflow Tables. In this case a ConcretePhysicalPhysical view may map more than one table.
may be generated from meta information, such as the table structure of the database.
Database
encapsulates the database management system. Provides methods for starting database connections, issuing database commands and receiving results.
We
shall discuss dynamic behavior with the patterns that implement the different
aspects of the framework.
When using the pattern you will come across the consequences listed in the „General Consequences“ Section on page 7.
Treatment of Mass Updates: Mass updates are statements of the form “update .. where”, which manipulate a set of records with a single query. It is hard to integrate these statements with the View Cache. Incorporating mass updates means: Perform a mass read into the ViewCache, manipulate single records, and write them back into the database one at a time. This solution is much slower than directly performing the task on the database.
Batches need special treatment. There is a set of patterns dealing with batch database access, which are waiting to be mined.
Multiple Read Queries: We have skipped multiple read queries. You can find further information in the Short Views and Narrow Views patterns.
Cursor Stability: There is the theoretical possibility to submit mass read operations to a BFIM (before images) consistency check. This would provide level 2 transaction consistency (cursor stability [Gra+93]) instead of level 1 (browse consistency). Mass read operations are typically used to fill list boxes (see Short Views). They have the form „select <fields> from ... where“. Checking them for consistency at commit time would mean rereading all read records read during the transaction and comparing them to their before images. If only a single record differs you have to abort the transaction. This is not only a serious threat to performance - it also does not add any value to consistency. In most cases records used to fill list boxes do not play any role that could flaw the consistency of a task. Hence, it is usually sufficient to use browse consistency for data not involved in computations during the transaction.
ConcretePhysicalViews and dynamic SQL: If the database system supports dynamic SQL without runtime penalty, you may skip the ConcretePhysicalViews and use the Query Broker to generate the appropriate SQL statements. For static SQL the ConcretePhysicalViews provide the queries.
Database Connections should remain established as long as possible. Establishing a new connecting for every Transaction shall result in bad performance.
The use of database triggers and stored procedures containing business logic is strongly discouraged with this architecture. A View Cache will not be notified about autonomous changes in the database. Hence stored procedures may cause cache consistency problems. Similar problems arise with triggers: Since they work on the physical data model it is hard to transform them to the logical level of the application kernel. However, you may use restricted stored procedures to speed up data access (see Physical Views).
Omitting
the ViewCache:
If you do not need long transactions, you may omit the ViewCache.
This is a feasible approach for simple dialog systems supporting only the
manipulation of a single record per transaction. However, you should use the ViewCache
if the application kernel has a notion of transactions affecting more than one
record.
A cache is the natural choice to implement user transactions on top of a transaction monitor, such as IMS, CICS, or UTM. Transaction monitors start a new transaction for every step the dialog takes while user transactions contain typically several dialog steps to complete. Using the ViewCache enables you to collect all write activities to the database that occur during a user transaction. They are later executed in a single technical host transaction preserving transaction integrity over multiple dialog steps of a transaction system.
Using non-relational Databases: The Physical Access Layer may also encapsulate non-relational databases and file formats, such as IMS-DB, CODASYL, or VSAM. You may even adapt to several different database technologies, thus hiding access to legacy data.
The pattern is an application of Layers [Bus+96, pp. 31]. The View Factory is an application of the Abstract Constructor [Lan96]
[Bro+96] and [Col+96] describe how to extend the pattern to offer an object-oriented view of a relational database to the application kernel. Brown and Whitenack [Bro+96] use a broker to decouple the layers while [Col+96] describes a hard-wired approach.
The VAA Data Manager specification uses this pattern together with editors for meta data and complex mappings for hierarchical database systems [VAA95]. The VAA Data Manger is derived from the Data Manager Architecture of Württembergische Versicherung [Würt96].
Denert sketches some basic ideas of the pattern language in [Den91, pp. 230-239]. Many projects at sd&m used the patterns in various variants including Thyssen, Deutsche Bahn, and HYPO Bank [Kel+96a].
The CORBA Persistent Object Services (POS) [Ses96] specify persistent objects that use a Broker (Persistent Object Manager) to write their data to arbitrary data stores (Persistent Data Services).
[1] Application data types are often used instead of raw database data types at application kernel level. They have additional methods to check their contents, reformat it, or format it for output. [Den91, chapter 5.2]
[2] Most database errors are not meaningful on application level. Therefore it is a good idea to translate them. Additionally you may have to translate the error mechanism when the database uses return codes to signal errors and your application uses exceptions.