Controlled Redundancy is a technique to use redundant fields in a physical database in order to speed up reading database access.
In the process of optimizing the order processing system you find out that clerks often produce a test invoice and check it at the screen before they confirm orders. They complain to you that this use case could be handled faster. From database trace protocols you find out that the queries for printing orders produce heavy database load.
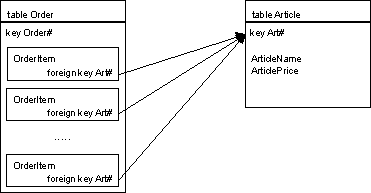
You did denormalize the Order table. But for a normal invoice with five positions you still have 7 databases accesses. One for the order and its positions, one for the customers data and 5 primary key accesses for the article data needed for five order positions. You consider this unacceptable.
How can you manage to read physical views with a single page database access when you need to read data from a parent entity?
The forces involved here are the same as in the Denormalization pattern.
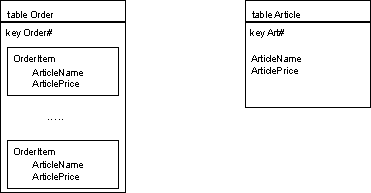
Replicate those parts of the parent entity (Article) in the child entity (OrderItem) that you need for the use case. Replicate only stable data that are not subject to frequent updates.
Time: You can considerably reduce the number of database pages accessed for read operations by using Controlled Redundancy. In case of write operations to the parent entity (Article) you will need additional database accesses as you have to update more than one table to write the same (redundant) fact.
Space: You need more database space for redundant data.
Code complexity: Controlled Redundancy results in more complex code as you pull application level considerations down to the database level. A database user must know that he or she also has to update the Order table if the name of an article changes. In any case Controlled Redundancy should be shielded and controlled by a Physical Access Layer. Never clutter code that accesses such data into the application kernel.
Queries: Redundancy does not impair the understandability of a physical data model. It might even improve understandability.
Controlled Redundancy should only be used for stable data. An article name will seldom change during the live span of an order. Redundant customer data like the customer’s name will also seldom change. It is acceptable to replicate such data. If it comes to an article price we may well start a discussion. If the price is fixed during the live span of the order, you will replicate it. If the price is subject to frequent updates you should consider the read / update performance tradeoff.
NarrowViews will motivate you to replicate only the data you really need for high performance use cases.