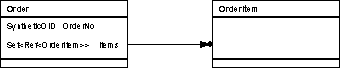
The pattern shows how to map 1:n associations between objects to relational tables
Consider the classic Order / OrderItem example. A valid Order may have from zero to many OrderItems.
How do you map an 1:n association to relational tables?
See the General Forces on page 1.
Insert the owner object’s OID into the dependent objects table. The OID may be represented by a database key or a Synthetic Object Identity.
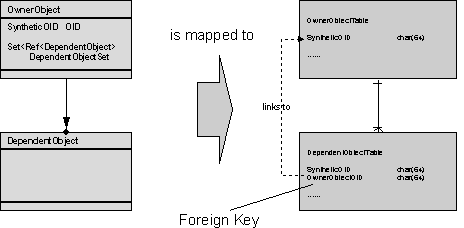
Read performance: Reading an Order object costs a join operation or two read operations - one of them multiple. You then have the Order object plus a set of references to all OrderItems.
Write Performance: Writing all owned objects in an 1:n association using the pattern costs the number of changed owned objects as you would not write unchanged objects.
Performance and redundancy versus maintenance cost and normal forms: The mapping scheme is the usual mapping scheme in relational database applications. It does not collide with normal forms. Hence it allows reasonable maintenance cost.
Space consumption is near optimal - except the space required for the foreign key column in the DependentObject’s table.
Ad-hoc queries: As the mapping is common in relational database applications, ad-hoc queries are not harder or easier to write than in any relational database application.
Application style: The mapping best suits relational style applications. You should not try to use a relational database for CAD or CASE applications. The reason for this lies exactly in mapping of associations to relational tables via foreign keys. Resolving an association costs a join operation or a second database access. Page based storage systems, such as OODBMS can handle similar use cases much faster but are worse at tuple processing - a stronghold of the relational model.
Integration of legacy systems: As most relational legacy systems use exactly the mapping described, converting 1:n associations to objects is no source of new problems.
General Performance: If performance turns out insufficient you might use a Relational Database Access Layer below the object/relational mapping and apply performance improvement patterns such as Controlled Redundancy, Denormalization, or Overflow Tables [Kel+97]. This allows you to later optimize physical table schemes without affecting the logical mapping scheme proposed by this pattern.
Update performance: When updating OrderItems (dependent objects) you should update only those that really have been changed and not each and every OrderItem that you did load into your working storage. Update and insert operations are expensive.
Prefetching dependent objects: In case you know in advance, that you need access to all dependent objects (like OrderItems) for most use cases, you can get all data using a join operation and construct the owner object and the dependent objects from the result of a single database operation like:
select * from Order O, OrderItem I
where O.key = ‘YourOrderKey’ and
O.key = I.OrderKey
This is faster than filling a container of Smart Pointers (Set<Ref<OrderItem>>) with object identities that have to be dereferenced one by one. For an Order with 20 OrderItems this costs 1 database access for the Order object, 1 multiple read access to get 20 object identities of the dependent objects plus 20 single record read accesses to get the OrderItem one by one.
In practice an 1:n association is often hard to distinguish from an aggregation. Therefore also consider the aggregation patterns Single Table Aggregation and Foreign Key Aggregation. The later is the same solution for a slightly different problem.
As an alternative to using foreign keys, consider Controlled Redundancy, Denormalization, and Overflow Tables .
The pattern is a close relative of Mapping n:m Associations using Association Tables. See also Representing Object Relationships as Tables [Bro+96].