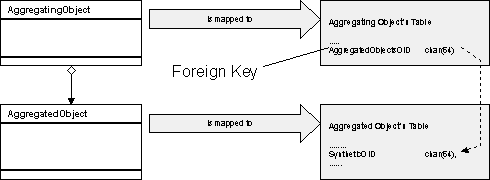
The pattern shows how to map aggregation to a relational data model using foreign keys.
Reconsider the example for Single Table Aggregation (see Figure 1 ). Presume you want a solution that treats the AddressType as a first class object and that allows better maintenance than Single Table Aggregation.
How do you map aggregation to relational tables?
See the Single Table Aggregation pattern.
Use a separate table for the aggregated type. Insert an Synthetic Object Identity into the table and use this object identity in the table of the aggregating object to make a foreign key link to the aggregated object.
The AggregatingObject is mapped to a table. The AggregatedObject is mapped to another table. The Aggregated Object’s Table contains a Synthetic Object Identity. This SyntheticOID is referenced by the AggregatedObjectsOID foreign key field in the Aggregating Object’s Table.
If we apply the solution to the example , we get a Customer Table that contains two foreign key references to the AddressType Table . The AddressType Table contains a Synthetic Object Identity field that is used to link the two tables.
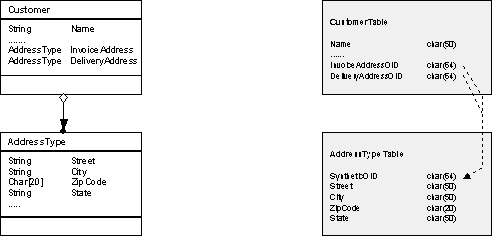
Retrieving a customer object from the database now costs three database access operations (one for the Customer and one for each AddressType, Invoice Address and DeliveryAddress) instead of one in the case of Single Table Aggregation.
This can be brought down to a single join database access, if the AddressType Table is equipped with an additional back link field that points to a Synthetic Object Identity of the Customer Table. The cost of this is getting a result set of two addresses, each with all the customer attributes.
Performance: Foreign Key Aggregation needs a join operation or at least two database accesses where Single Table Aggregation needs a single database operation. If accessing aggregated objects is a statistical rare case this is acceptable. If the aggregated objects are always retrieved together with the aggregating object, you have to have a second look at performance here.
Maintenance: Factoring out objects like the AddressTypes into tables of their own makes them easier to maintain and hence makes the mapping more flexible.
Consistency of the database: Aggregated objects are not automatically deleted on deletion of the aggregating objects. To perform this task you have to provide and maintain application kernel code or database triggers. This is also an implementation issue. You have to chose one of these two options.
Ad-hoc queries: Factoring out aggregated objects into separate tables allows easy querying these tables with ad-hoc queries.
Consider using domain keys instead of Synthetic Object Identities. Domain keys have the drawback that they cannot be used for arbitrary links pointing back to an owner object as the owned object type cannot know all types of objects that will ever own it.
Consider inserting a link back from the aggregated object to the aggregating object. In our address example this is accomplished by inserting a field into the address table that stands for the owner of the AddressType object. As the owner may be an Employee, a Customer or some other type that aggregates the AddressType you have to use a Synthetic Object Identity as the link’s type. Bi-directional links offer some advantages for queries, consistency checking and other purposes. You don't have to search the aggregating object's table to find an owner of an aggregated object. On the other hand, backlinks are more expensive in terms of database operations needed to keep them up to date.
For an alternative see Single Table Aggregation. Foreign Key Association works very similar. See also Representing Collections in a Relational Database [Bro+96].