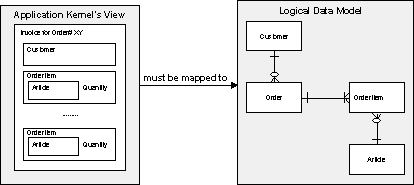
You are programming a task that needs a large volume of data at a time. You know the structure of these data the moment you enter the use case in which you process them. Have a look at the invoice example below that is explained in more detail in the Accessing Relational Database Pattern Language[Kel+98a ]. Now consider you want to build an high speed online browser for large invoices.
Figure
15:
Part of an Order Processing System
It's not good idea to read an invoice object, dereference a customer proxy, dereference n order position proxies plus n proxies for each product. This would require 1 + 1 + n + n calls to the database over the network, consuming from 200 to 500 Milliseconds each.
How do you provide high performance access to large chunks of data via an object/relational access layer?
Performance versus complexity and cost: relational databases are missing a concept of clusters across multiple records that allows reading larger chunks of data across tables at a time - at least they do not support it at the level of query languages like SQL. Building something that is able to handle larger chunks of date or clusters will increase the complexity of your access layer.
Write a stored procedure or an access layer module that contains a series of SQL queries that get exactly the data that you want - all at the same time.
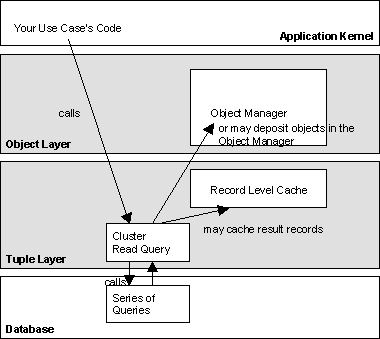
Figure
16:
Calling a Cluster Read Query
You call the cluster read operation (usually a module of the tuple layer) directly from the application kernel. The module will deposits its results in a record level cache below the object manager. It might as well create objects from the results and place them directly in the object manager depending on the complexity of your mapping.
Applying the Cluster Read pattern to the above example will yield only one database request plus a reduced number of database accesses, depending on the physical structure of the database.
Performance: You economize on database calls, potentially over a network and get rid of lots of call overhead. The pattern can speed up complex use cases by up to 90%.
Maintenance: If you "hack" cluster reads based directly on the physical database scheme, you will get a maintenance problem when the physical structure of the database changes. This is affordable as you usually only need a few dozen cluster reads even in large scale applications.
Cluster Read is a form of request bundling and so resembles Bundled Write. It uses exactly the idea behind Logical Views, so it is pretty common in all host based transaction systems that handle large amounts of data for single use cases. Cluster read may also be used with optimization patterns like denormalization, overflow tables and so on.
Reading data by clusters and request bundling are ubiquitous. The basic idea of Clustering is used in many storage subsystems. The pattern in this form is used in the Phoenix Persistence subsystem [Sta+97 ] by EA Generali. Complex stored procedures are used for similar reasons.