OBJEKTspektrum Juli/August 1996, Nr. 4, Seite 20-28.
Jens Coldewey, Wolfgang Keller
Viele Unternehmen versprechen sich von einem Einstieg in objektorientierte Technologie verbesserte Möglichkeiten zur Wiederverwendung und die einfachere Entwicklung von verteilten Systemen. Gerade bei Großanwendern, wie Banken und Versicherungen, werden dabei häufig bestehende Systeme abgelöst, die eine monolithische, transaktionsorientierte Architektur aufweisen. Eine "Stichtagsablösung" ist riskant und meist auch nicht durchführbar. Der Artikel diskutiert die objektorientierte Datenintegration als Migrationsstrategie, bei der Altsysteme und neue Applikationen auf den gleichen Datenbeständen arbeiten. Die typischen Probleme werden erläutert und Lösungswege skizziert.
Viele EDV-Großanwender, wie Banken und Versicherungen, stehen heute vor der Entscheidung, objektorientierte Software-Entwicklungsmethoden einzuführen, oder haben bereits erste Pilotprojekte gestartet. Am Anfang des Migrationsprozesses stehen meist monolithische, großrechnerbasierte Transaktionssysteme unterschiedlicher Qualität. Am Ende des Prozesses sollen eine objektorientierte Systemarchitektur sowie eine Entwicklungsmannschaft stehen, die auf das neue Denken gründlich eingeschworen ist. Dabei müssen die immensen Investitionen geschützt werden, die gerade große Anwender in den letzten Jahrzehnten in ihre Softwaresysteme getätigt haben. Bei diesen Kunden treten technische Probleme der Objektorientierung meist zugunsten wirtschaftlicher Abwägungen in den Hintergrund. Voraussetzung einer erfolgreichen Migration ist eine genau auf die Bedürfnisse des einzelnen Kunden abgestimmte Strategie. Diese darf nicht nur einzelne Applikationen betrachten, sondern muß die gesamte EDV-Landschaft des Unternehmens in die Planung der Migrationsstrategie einbeziehen.
Stichtagsablösungen bergen gerade bei Großanwendern
nicht kalkulierbare Risiken - vielleicht ein Grund dafür,
daß sie im Englischen doppeldeutig als Big Bang Strategies
bezeichnet werden. Zweihundert und mehr Entwickler sowie millionenschwere
Investitionen in die EDV-Landschaft können nicht mit einem
großen Knall auf ein neues Paradigma umgestellt werden (vgl.
[Ebe94]). Bei solchen Unternehmen ist
eher damit zu rechnen, daß der Übergang zur Objektorientierung
zehn und mehr Jahre dauert. Während dieser Zeit müssen
alte und neue Systeme parallel betrieben und auch weiterentwickelt
werden. Diese Anforderung ist bei vielen EDV-Anwendern ein zentrales
Kriterium, an dem sich jede Migrationsstrategie messen lassen
muß.
In der Praxis bieten sich verschiedene Ansätze für eine objektorientierte Teilrenovierung von Systemen an:
Eine Migrationsstrategie zur Objektorientierung wird sich bei Großkunden niemals auf einen einzelnen dieser Wege konzentrieren.
Üblicherweise wird der Übergang auch noch in mindestens drei Phasen eingeteilt:
Welche der beschriebenen Strategien eingesetzt wird, hängt vor allem von der individuellen Kosten/Nutzen- und Risikobewertung des Unternehmens ab. Dabei sollten das bestehende Altsystem und das projektierte Neusystem unter verschiedensten Gesichtspunkten betrachtet werden. In unserer Praxis hat sich der Einsatz der folgenden, groben Checkliste bewährt:
Im Lichte dieser Kriterien werden in einer Pilotphase vor allem GUI-Migrationen und Offline-Systeme in Frage kommen. In späteren Phasen werden die Zwischenlösungen eher mit Proxy-Objekten oder mit Hilfe von Datenintegration realisiert. Während Proxy-Objekte stark anwendungsspezifisch sind, hat sich in den letzten Jahren eine Standardlösung zur Datenintegration entwickelt, die wir im folgenden näher betrachten wollen.
Gerade Großanwender, wie Banken und Versicherungen, haben bereits in den sechziger Jahren mit der Automatisierung ihrer Geschäftsprozesse begonnen. In der Regel läuft in diesen Unternehmen daher heute Software aus drei Generationen:
Objektdatenbanken sind erst seit wenigen Jahren auf dem Markt und spielen derzeit außerhalb von Pilotprojekten kaum eine Rolle im kommerziellen Umfeld von Großanwendern. Es ist jedoch damit zu rechnen, daß sich dies im Laufe der nächsten Jahre deutlich ändern wird. Insbesondere Systeme zur Unterstützung strategischer Entscheidungen werden mehr und mehr Nutzen aus Objektdatenbanken ziehen können. Eine vollständige Verdrängung von relationalen Systemen ist derzeit aber nicht wahrscheinlich, da die beiden Paradigmen sehr unterschiedliche Stärken und Schwächen haben (vgl. [Cha96]).
Um in diesem "Zoo von Technologien" effektiv Software entwickeln zu können, haben viele Unternehmen sogenannte Tupelschnittstellen entwickelt. Diese Komponenten kapseln den Zugriff auf die verschiedenen Datenbanktechnologien und bieten der Applikation eine einheitliche Schnittstelle für alle Daten. Die angebotene Sicht ist in der Regel vergleichbar mit einer relationalen Datensicht, wobei aber nur statische Abfragen zulässig sind. Solche Tupelschnittstellen unterstützen allerdings objektorientierte Anwendungen noch nicht optimal (siehe [Cat94]). Will man eine objektorientierte Sicht auf die Unternehmensdaten zur Verfügung stellen, stößt man auf eine Reihe schwieriger Probleme, die sich erst bei näherem Studium der Materie offenbaren - oder beim Systemtest.
Es gibt zwei grundsätzlich verschiedene Ansätze, aus einer objektorientierten Anwendung auf relationale Datenbanken zuzugreifen:
Bei der Datenintegration soll der Anwendungskern objektorientiert gebaut werden, weshalb wir uns auf die Persistenz von Objekten konzentrieren. Wir wollen zunächst die Anforderungen an eine Zugriffsschicht erläutern, um dann die Komponenten üblicher Lösungen vorzustellen.
Die Abbildung von der objektorientierten Sicht des Anwendungskerns auf die Tupelschnittstelle erfolgt grundsätzlich nach dem in Abbildung 1 dargestellten Schema. Leider birgt diese einfache Abbildung einige Fallen und Probleme, auf die wir im folgenden genauer eingehen möchten.
| 1 Klasse | 1 Tabelle | |
| 1 Instanz | 1 Zeile | |
| 1 Attribut | 1 Feld | |
Viele objektorientierte Programmiersprachen (zum Beispiel C++, Eiffel und Java) haben ein komplexes Typkonzept mit Ausschnitts- und Verbundtypen. Zusätzlich stehen Listen, Mengen und ähnliche Konstrukte zur Verfügung, die in Form von Klassenbibliotheken in das System integriert werden. Die üblichen relationalen Datenbanken kennen hingegen nur Zahlen und Zeichenketten in einigen festen Variationen. Die einzige Möglichkeit zur Strukturierung besteht in der Zusammenstellung von Tabellen.
Zur Überwindung dieser Lücke müssen hierarchische Typen "flachgeklopft" bzw. wieder zusammengefügt werden. Auch Listen, Mengen und ähnliches, die in objekt- orientierten Sprachen selbst wieder durch Objekte realisiert werden, müssen einer besonderen Behandlung unterworfen werden. Datenbanken unterstützen gerade die Arbeit mit Massendaten in besonders performanter Weise, so daß ein zu naiver Ansatz hier zu einem katastrophalen Leistungsverhalten führt.
In relationalen Systemen werden Sätze innerhalb einer Tabelle einzig durch ihren Inhalt identifiziert: Über einen Schlüssel kann ein Satz im allgemeinen eindeutig gefunden werden.
In der objektorientierten Welt besitzen Objekte dagegen eine eigene Identität, unabhängig von ihrem Inhalt. Dadurch entstehen drei Probleme:
| Ein Versicherungssystem soll die Möglichkeit bieten, mit einem Kunden mehrere Vertragsabschlüsse gleichzeitig nach dem "Alles-oder-Nichts-Prinzip" zu tätigen. Um eine finanzielle Überlastung des Kunden durch das Vertragspaket zu vermeiden, ist vor dem Abschluß jedes einzelnen Vertrages die Bonität des Kunden zu überprüfen, wobei die bereits abgeschlossenen Verträge berücksichtigt werden sollen. Zur Prüfung der Bonität wendet sich der Anwendungskern jedes Mal an die Datenbank, um das Objekt Kunde XY zu holen.
Wenn die Zugriffsschicht in diesem Szenario nicht beachtet, daß bei jedem Zugriff das bereits anfangs geholte Objekt Kunde XY gefordert ist, und statt dessen jedesmal ein neues Objekt aus der Datenbank holt und im Speicher neu erzeugt, so spiegelt dieses neue Objekt den Stand in der Datenbank wider und berücksichtigt die bisher abgeschlossenen Verträge nicht: Der Geschäftsvorfall wird fehlerhaft bearbeitet, da die Vertragsabschlüsse mit einem anderen Objekt durchgeführt werden als die Bonitätsprüfungen. |
Objektorientierte Systeme weisen in der Regel eine große Anzahl relativ einfacher Klassen auf, die über sehr komplexe Beziehungen miteinander interagieren. Die fachliche Komplexität eines Problems wird beim objektorientierten Design nicht so sehr durch komplexe Algorithmen repräsentiert, sondern eher durch die Komplexität der Beziehungen zwischen Objekten.
Relationale Systeme unterstützen Beziehungen nur in Form der Fremdschlüssel-Beziehung. Diese werden mit Hilfe von Select- oder Join-Operationen der Datenbank verfolgt, die aufwendig sind. Hier muß man beim Paradigmenwechsel besondere Vorsicht walten lassen.
Wichtig ist es hier, von der einfachen Formel 1 Klasse <-> 1 Tabelle abzuweichen. Dies ist insbesondere bei Aggregationen sinnvoll: Man stelle sich vor, für die Klasse Datum, die in den meisten Systemen vorhanden ist, würde eine eigene Tabelle erzeugt, die nur alle Datumsangaben in der Datenbank enthält! Daß ein solcher Entwurf nicht sinnvoll sein kann, ist intuitiv klar. Niemand käme auf die Idee, ein relationales System so zu bauen.
Zu beachten ist auch, daß Beziehungen in objektorientierten Sprachen immer unidirektional, also gerichtet, sind, während Fremdschlüssel-Beziehungen in relationalen Systemen immer in beiden Richtungen verfolgt werden können. Insbesondere zweiseitig verfolgbare 1:n -Beziehungen lassen sich in objektorientierten Systemen nur mit zusätzlichem Aufwand implementieren, indem z. B. Listen von Referenzen statt eines Fremdschlüssels eingesetzt werden.
Vererbung und Polymorphismus sind zwei zentrale Elemente des objektorientierten Paradigmas. Die Wartbarkeit eines gut entworfenen OO-Systems ist vor allem der Möglichkeit zu verdanken, ähnliche Klassen durch Vererbung und Polymorphismus wie eine Klasse behandeln zu können.
Relationale Systeme sehen diese Möglichkeit nicht vor. Zwar bietet die Entity/Relationship-Modellierung (Abk. E/R-Modellierung) die Möglichkeit, sogenannte "Ist-ein-Beziehungen" zu formulieren, doch die meisten Datenbanksysteme bieten dafür keine direkte Implementierung an. Das Problem der Umsetzung zerfällt bei genauerer Betrachtung in zwei Teilprobleme:
Die Zugriffsschicht muß also sowohl die Vererbungshierarchie kennen, als auch den exakten Typ eines Objekts, das sich in der Datenbank befindet. Sie muß in der Lage sein, Objekte typrichtig zu erzeugen und polymorph an den Anwendungskern zurückzugeben.
Bis jetzt haben wir uns nur mit Problemen beschäftigt, die direkt mit dem Paradigmenbruch zusammenhängen. Viele moderne Anwendungen benötigen zusätzlich eine Flexibilisierung des Transaktionskonzeptes. Klassische Transaktionssysteme sind darauf optimiert, genau definierte, kurze Geschäftsvorfälle stark parallelisiert abzuarbeiten. Ein Kontoführungssystem einer Bank muß Millionen von kurzen Einzelbuchungen pro Tag abarbeiten. In den letzten Jahren wurden jedoch verstärkt Systeme entwickelt, die Beratern oder Managern bei ihren Entscheidungen helfen. Solche Systeme unterstützen Geschäftsprozesse, die mehrere Stunden oder gar Tage dauern und dem Anwender ein hohes Maß an Flexibilität bieten. Für diese unterschiedlichen Arten von Geschäftsprozessen muß die Datenbank verschiedene Transaktionen anbieten:
Da die Wahl der Transaktionslogik von der jeweiligen Anwendung abhängt, sollte die Zugriffsschicht beide Möglichkeiten bieten.
Relationale Datenbanken stellen ein eigenes Konzept dar, das unabhängig von der Programmiersprache ist. Persistente Objekte fügen sich dagegen nahtlos in die Programmiersprache ein. Daher ist es sinnvoll zu fordern, daß sich der Anwendungscode von Persistente Objekten nicht von dem transienter Objekte unterscheiden soll. Die Funktionen der Datenhaltung sollten mit den üblichen Mitteln der Programmiersprache formuliert und Spracherweiterungen vermieden werden.
void beispiel ( d_String kundenName ) {
|
Die "Object Database Management Group" (Abk. ODMG) standardisiert die Schnittstelle von Objektdatenbanken (vgl. [ODMG96]). Nicht alle Aspekte dieses Standards sind im Rahmen der Zugriffsschicht interessant. Die Programmierschnittstelle der Zugriffsschicht sollte sich jedoch möglichst an die ODMG-Sprachanbindung der gewählten Sprache halten. Dies erspart die ansonsten notwendigen Konzeptarbeiten und erleichtert den Programmierern die Einarbeitung in die Zugriffsschicht, da sie auf Standardliteratur zurückgreifen können. Ferner kann die Zugriffsschicht später leichter durch eine normkonforme Objektdatenbank ausgewechselt werden.
Die für die Zugriffsschicht benötigten Methoden können
zu großen Teilen automatisch erzeugt werden. Existiert kein
Altsystem, kann die Zugriffsschicht sogar vollständig generiert
werden (vgl. [Hah95]), da keine Rücksicht
auf bestehende Datenbankschemata genommen werden muß. Implementierungen
für C++ können durch den Einsatz von Templates auf Generierung
verzichten. Die Generierung wird dann vom Compiler erledigt. Sollen
bestehende Datenbestände genutzt werden, so muß allerdings
das "Mapping", also die Umsetzung zwischen dem Tabellenschema
und den Objekten, manuell erfolgen.
Um eine verwendbare Anwendung zu erhalten, müssen normalerweise innerhalb der Zugriffsschicht noch gezielt Optimierungen vorgenommen werden. Das können z. B. Denormalisierungen des Datenbankschemas sein oder Cache-Techniken mit fachlichem Know-how (sogenannte Look-Ahead-Caches). Da solche Optimierungen in der Regel erst nach ausführlichen Leistungsmessungen am laufenden System vorgenommen werden, muß man zentrale "Schrauben" vorsehen, an denen diese Optimierungen mit möglichst geringem Aufwand durchgeführt werden können.
Um nicht nur über Probleme und Anforderungen zu schreiben, wird es Zeit, eine Lösung vorzustellen, die über fünf Jahre aus dem in [Hah95] beschriebenen System weiterentwickelt wurde. Wir werden die wesentlichen Elemente im folgenden kurz diskutieren. Eine technisch erschöpfende Behandlung des Themas ist im Rahmen eines kurzen Artikels allerdings nicht möglich.
Zunächst soll am Beispiel von C++ ein Gefühl für die mögliche Spracheinbettung vermittelt werden. Listing 1 zeigt einige Operationen auf einem persistenten Objekttyp Kunde; hierzu gehören:
Der Objekttyp Kunde besitzt neben fachlichen Methoden auch Methoden der Zugriffsschicht.
Die Schnittstelle lehnt sich an die C++-Sprachanbindung der ODMG an. Sie setzt sich zusammen aus ererbten Methoden (wie markModified), generierten Methoden (wie d_getByName) und eigenen Klassen (wie d_Transaktion).
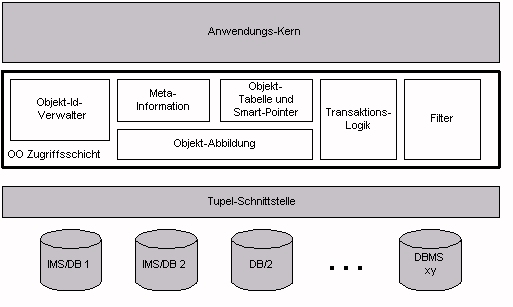
Die Architektur, die die Datenbank hinter dieser Schnittstelle versteckt, ist in Abbildung 3 dargestellt. Die Komponenten werden im folgenden einzeln erläutert.
Der komplexeste Teil einer Zugriffsschicht ist die Abbildung der Objekte auf die relationale Datenbank. Sie sorgt dafür, daß Objekte sich aus der Datenbank laden und in eine Datenbank zurückschreiben können. Die Umwandlung kann für Attribute und Beziehungen getrennt betrachtet werden.
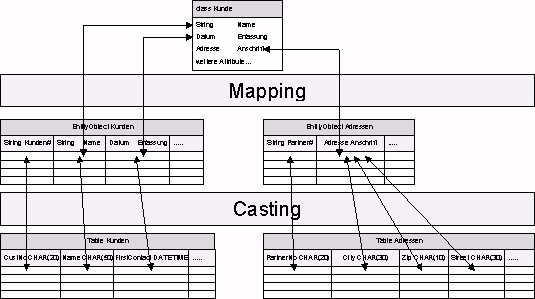
Um komplexe Typen einer objektorientierten Sprache auf das einfach Typsystem der Datenbank umzuwandeln, wird im wesentlichen Attribut für Attribut konvertiert. Diese Konvertierung läßt sich in zwei Teilaufgaben zerlegen: "Mapping" und "Casting" (siehe Abbildung 4):
Beim Mapping wird für jedes Attribut einer Klasse angegeben, aus welchen Feldern der Datenbank der Wert beschafft werden kann. Das Casting setzt dann den Typ der Programmiersprache in den Typ der Datenbank um. Handelt es sich bei dem Attribut um einen Verbundtyp, so wird er beim Mapping auf ein komplexes Pseudofeld der Tabelle abgebildet und beim Casting aufgebrochen.
Auch die Vererbung von Attributen muß von der Objektabbildung gelöst werden. Hier sind zwei Alternativen denkbar:
Bei Beziehungen muß man zwischen einfachen Beziehungen (1:1 ) und mehrfachen Beziehungen (1:n und n:m ) unterscheiden. Einfache Beziehungen lassen sich problemlos durch Fremdschlüssel-Beziehungen realisieren. Soll die Beziehung auch im Objektmodell bidirektional sein, so werden auf beiden Seiten der Beziehung Referenzen gehalten, deren Konsistenz von den Methoden der Zugriffsschicht sichergestellt wird. Man sollte allerdings in Objektmodellen im Gegensatz zu E/R-Modellen sehr sparsam mit wechselseitigen Beziehungen sein, da sie eine enge gegenseitige Abhängigkeit zwischen den Klassen erzeugen, welche Entwicklung und Wartung erschwert.
Schwieriger ist die Modellierung von mehrfachen Beziehungen. Hier wird im Objektmodell auf Container aus Klassenbibliotheken - z. B. Listen oder Mengen - zurückgegriffen. Bei der konkreten Implementierung muß die Unterstützung der Datenbank für Massenzugriffe ausgenutzt werden, um eine gute Performanz zu erhalten.
Eine Objekt-Id (Abk. OID ) ist ein systemweit eindeutiger Identifikator für eine Objektinstanz. Er enthält üblicherweise neben einem Kunstschlüssel auch Informationen über die Klasse des Objekts.
Müssen keine Altsysteme auf die Daten zugreifen, können die OIDs als eigene Spalte der Datenbanktabelle abgespeichert werden. Darf bei Altanwendungen das Datenbankschema nicht verändert werden, so muß ein spezieller OID-Verwalter erstellt werden, der den Tabellennamen und den Primärschlüssel der Tabelle als OID einsetzt. Dieser klassenspezifische OID-Verwalter erbt von dem Standard-Verwalter, um Redundanz und Fallunterscheidungen zu vermeiden.
Soll auf ein bestimmtes, persistentes Objekt zugegriffen werden, so muß das Objekt zunächst aus der Datenbank geladen werden. Dies geschieht über spezielle Klassenmethoden, die Dereferenzierungsmethoden. Diese Methoden überprüfen anhand der OID in der Objekttabelle, ob das gewünschte Objekt bereits geladen ist. In der Objekttabelle werden Referenzen auf alle derzeit in den Prozeß-Adreßraum geladenen Objekte gespeichert. Ist die Instanz noch nicht geladen, so wird der entsprechende Datenbankzugriff ausgelöst, ansonsten wird eine Referenz auf die gesuchte Instanz zurückgegeben. Zusammen mit der OID-Verwaltung wird durch diesen Mechanismus die Objektidentität sichergestellt. Die Derefenzierungsmethoden werden in C++ über "Smart Pointer" gekapselt.
Um polymorphe Zugriffe richtig bearbeiten zu können, benötigt die Zugriffsschicht Informationen über die Vererbungshierarchie der Anwendung. Sie muß z. B. wissen, daß Anfragen auf die abstrakte Klasse Kunde nicht die Tabelle Kunde betreffen, sondern die beiden Tabellen PrivatKunde und GeschäftsKunde. (siehe Listing 2).
Die Zugriffsschicht muß wissen, wie sie Objekte des gewünschten Typs erzeugen kann. Diese Informationen verwaltet die in Abb. 3 dargestellte Komponente Meta-Information, indem sie den Vererbungsbaum als einen Baum von Prototypen anlegt (vgl. [Gam95]). Mit Hilfe dieser Prototypen erzeugt die Zugriffsschicht anhand der Typinformationen in der OID den dynamisch korrekten Typ unabhängig von der Anfrage. Die Meta-Information löst dadurch das Problem des dynamischen Bindens.
| class PrivatKunde : Kunde {...};
class GeschaeftsKunde : Kunde {...}; ... d_Set<d_Ref<Kunde>> dieKunden; ... dieKunden = Kunde::d_getSome (...); // Die Instanzen sind von mehreren Subtypen, stehen also in unterschiedlichen Tabellen |
Abfragen an die Datenbanken arbeiten mit Filterobjekten; das sind Objekte, die alle Parameter einer Anfrage aufnehmen, um dann an die Abfragemethode übergeben zu werden. Filter sind eine "Billigvariante" einer Object Query Language (Abk. OQL). Sie können sehr speziell sein, z. B. auf die Attribute einer bestimmten Klasse filtern, oder sie können völlig allgemein gehalten werden, indem sie einfach einen SQL-String aufnehmen. Durch diese große Flexibilität sind Filterobjekte besonders gut geeignet, Abfragen zu modellieren. So lassen sich z. B. Beschränkungen auf statische Abfragen einfach dadurch modellieren, daß es nur spezielle Filterobjekte gibt, die genau diese Abfragen implementieren.
Die Transaktionskomponente realisiert optimistische Transaktionen und bietet beim Starten einer Transaktion die Auswahl, ob optimistisch oder pessimistisch gesperrt werden soll. Für optimistische Logik stützt sie sich auf Zeitstempel, die jedem Objekt als Attribut mitgegeben werden. Beim Beenden einer Transaktion werden die betroffenen Tabellen gesperrt, und die Zeitstempel der Objekte werden mit denen in der Datenbank verglichen. Stimmen die Stempel nicht überein, so ist ein Konflikt aufgetreten, und die Transaktion scheitert.
Hier tauchen besondere Probleme bei der Migration auf: Wie werden die Zeitstempel aktualisiert, wenn andere Anwendungen schreibend auf die Tabelle zugreifen? In diesem Zusammenhang hat sich die Lösung bewährt, einen Datenbank-Trigger auf die entsprechenden Tabellen zu setzen. Im Rahmen dieses Triggers werden dann die Stempel aktualisiert. Dieses Vorgehen ist für die Altanwendungen völlig transparent. Es ist jedoch nur durchführbar, wenn die Datenbank Trigger unterstützt und diese nicht bereits von einer Anwendung belegt sind. Ist das nicht der Fall, so ist die optimistische Transaktionslogik nicht realisierbar.
Daß Änderungen immer nur am Ende einer Transaktion komplett in die Datenbank geschrieben werden, kann auch dazu benutzt werden, die kurzen Transaktionen von Systemen wie IMS oder CICS zu überlisten. Die Zugriffsschicht generiert hier am Ende einer logischen Transaktion einen kurzen Stapellauf, der als eine Transaktion des Transaktionssystems ausgeführt werden kann (vgl. [Kel96]).
Die dargestellte Architektur ist auf typische Aufgabenstellungen interaktiver objektorientierter Anwendungen ausgelegt - also auf das Einlesen einzelner Objekte zur Bearbeitung durch den Benutzer. Bessere Performanz läßt sich nur noch durch den Einsatz von Objektdatenbanken erreichen, mit denen sich - für geeignete Anwendungen mit komplexen Objektgeflechten - noch einmal Beschleunigungen um den Faktor 10 bis 100 erreichen lassen. Seit neuestem gibt es eine zunehmende Anzahl von Produkten, die Objektdatenbanken und Host-Systeme koppeln können. Wir haben mit diesen Produkten allerdings noch keine praktische Erfahrung sammeln können.
Die dargestellte Architektur ist darauf ausgerichtet, daß Aktionen vom Anwendungskern angestoßen und in der Datenbank durchgeführt werden. Das bedeutet umgekehrt aber, daß keine Massenverarbeitung möglich ist, wie sie in SQL mit Befehlen wie UPDATE ... WHERE ... angestoßen werden. Anwendungen, die vor allem auf solche Konstrukte bauen, sollten nicht mit dieser Architektur gebaut werden, da sie keine klare Trennung zwischen Datenbank und Anwendungskern aufweisen.
Die Zugriffsschicht sieht es nicht vor, durch Trigger ausgelöste Änderungen der Datenbank im Anwendungskern nachzufahren. Zwar lassen sich theoretisch Datenbank-Trigger auch in der objektorientierten Welt durch Observer modellieren (vgl. [Gam95]), doch sollte dabei beachtet werden, daß diese Trigger vom physikalischen Datenbank-Layout ausgehen, also nicht unbedingt eindeutig einem Objekt zugeordnet werden können. Außerdem wären dazu Änderungen in
den "Stored Procedures" alter Anwendungen nötig. Die gleichen Probleme
erschweren die Datenintegration, wenn alte "Stored Procedures" oder "Integrity Constraints" existieren.
Die Datenintegration ist eine für Online-Systeme bewährte Migrationsstrategie im Umfeld großer EDV-Systeme. Dabei sind allerdings eine ganze Reihe technischer Probleme zu lösen, für die es in zunehmendem Maß auch fertige Produkte gibt. Die zu lösenden Probleme bleiben allerdings gleich, so daß dieser Artikel auch als Checkliste für Produkte dienen kann. Insbesondere der Zugriff über Transaktionssysteme auf Großrechner-Datenbanken und der Zugriff auf beliebig schlecht strukturierte Altdatenbestände werden aber bisher nicht ausreichend abgedeckt (vgl. [Kel96]). Ob derzeit erscheinende Produkte die Anforderungen abdecken werden, muß sich in der Praxis noch zeigen.
Viel Aufwand ist für die Bewältigung von Problemen zu erbringen, die mit Datenbankfunktionalität unmittelbar nichts zu tun haben. So ist zum Beispiel die Integration einer Zugriffsschicht in das Sicherheits- und Rechnerbetriebssystem ein nicht zu vernachlässigender Punkt. Herkömmliche Transaktionssysteme wie IMS und CICS bieten hier einfache Lösungen und gute Überwachungsmöglichkeiten, die teuer nachgebaut werden müssen, wenn man als Großanwender nicht auf sie verzichten kann.
Ein wichtiger Zusatznutzen eines Migrationsprojektes nach der vorgestellten Methode kann ein Generator für konventionelle Datenbank-Zugriffsschichten auf dem Host sein. Man kann Zugriffsmodule einer Tupelschnittstelle so konstruieren, daß sie für objektorientierte und konventionelle Anwendungen geeignet sind. Ist bei einem Anwender eine solche konventionelle Datenbankzugriffsschicht noch nicht vorhanden, kann alleine daraus oft schon der Nutzen für ein Zugriffsschicht-Projekt gerechtfertigt werden.
[Cat94] R.G.G. Cattell, Object Data Management, Addison-Wesley 1994
[Cha96] A.B. Chaudhri, P. Osmon, Databases for a New Generation -- What are the Options for Managing Persistent Objects?, in: Object Expert, S. 26ff., März/April 1996
[Ebe95] K. Eberhardt, S. Kutscha, Veraltete Systeme hemmen Innovation -- Altsystem-Abhängigkeit ist wichtiger als High-Tech-Themen, in: Computerwoche CW-Extra, 17. Februar 1995
[Gam95] E. Gamma, R. Helm, R. Johnson, J. Vlissides, Design Patterns, Elements of Reusable Object Oriented Software, Addison-Wesley, 1995
[Hah95] W. Hahn, F. Toennissen, A. Wittkowski: Eine objektorientierte Zugriffsschicht zu relationalen Datenbanken, in: Informatik Spektrum 18(Heft 3/1995); S. 143-151, 1995
[Kel96] W. Keller, Ch. Mitterbauer, K. Wagner, Objektorientierte Datenintegration über mehrere Technologiegenerationen, Proceedings ONLINE, Kongress VI, Hamburg 1996
[ODMG96] R.G.G. Cattell (Ed.) et. al., Object Database Standard (ODMG 93), Release 1.2; Morgan Kaufmann Publishers, 1996
Jens Coldewey (E-Mail-Adresse: jensc@sdm.de) und Wolfgang Keller (E-Mail-Adresse: wk@sdm.de) sind Berater bei der Firma sd&m, software design & management GmbH & Co. KG. Sie begleiten Großkunden bei der Einführung objektorientierter Technologie. Beide arbeiten derzeit in dem vom BMBF geförderten Projekt ARCUS, das sich mit Entwurfsmustern für die objektorientierte Software-Architektur betrieblicher Informationssysteme befaßt (WWW-Adresse: http://www.sdm.de/g/arcus/).