Imagine you write a batch job that processes life insurance policies. You have to process about 60.000 policies in one or two night batches. This means you have something like 700 milliseconds per policy. An analysis of the number of tables you have to update indicates, that each policy will cause about 70 inserts into a relational database at 100ms per update this is 7 seconds for the updates alone even on a very powerful host computer.
How do you handle output to a database when your database seems far too slow?
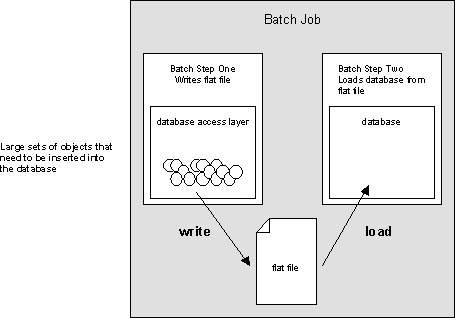
Performance of relational database against advantages of using them: There are situations when a relational database system simply seems too slow at a first glance, but you don't want to go back to using hierarchical database systems for the whole system just to support that one batch job. Loading a relational database from a flat file is usually at least one order of magnitude faster than individual inserts and updates.
Correctness versus Performance: Your results have to be correct - you cannot afford to lock large regions of the database for days and you cannot afford to allow errors.
Cost and Complexity: The solution should work with normal hardware at reasonable cost.
Write the records to a transaction secured flat file (VSAM or the like) and load the database from that file later. Note that this solution works for inserts only. In case of updates you have to merge your file with another file that contains the unloaded content of your database.
Performance: Your performance problem will be solved in most cases.
Correctness: Your batch should refer to only the data that you are processing, otherwise you will have pending updates in your flat files that will result in lost updates.
Cost and Complexity: You have to design a database access layer that is able to redirect its output to flat files. This is straightforward and not too expensive to implement.
You can see this pattern as a specialized version of store for forward. You use a very fast way to store your data in a form that is not the final one and forward them to the final destination (the relational database) later.
Many large scale batch jobs use the pattern. We will use it in the Phoenix project for the batch job described in the example. Many other insurance projects have used it so far.